Baekjoon14002 - 가장 긴 증가하는 부분 수열 4 (Python)
Baekjoon14002 - 가장 긴 증가하는 부분 수열 4 (Python)
백준 사이트 14002 - 가장 긴 증가하는 부분 수열 4 문제입니다.
이 글을 보시기 전에 문제를 풀기 위해 충분한 생각을 하셨나요? 답을 안 보고 푸는게 최대한 고민하는게 가장 중요하다고 생각합니다.!!
☑️ 1. 문제
https://www.acmicpc.net/problem/14002
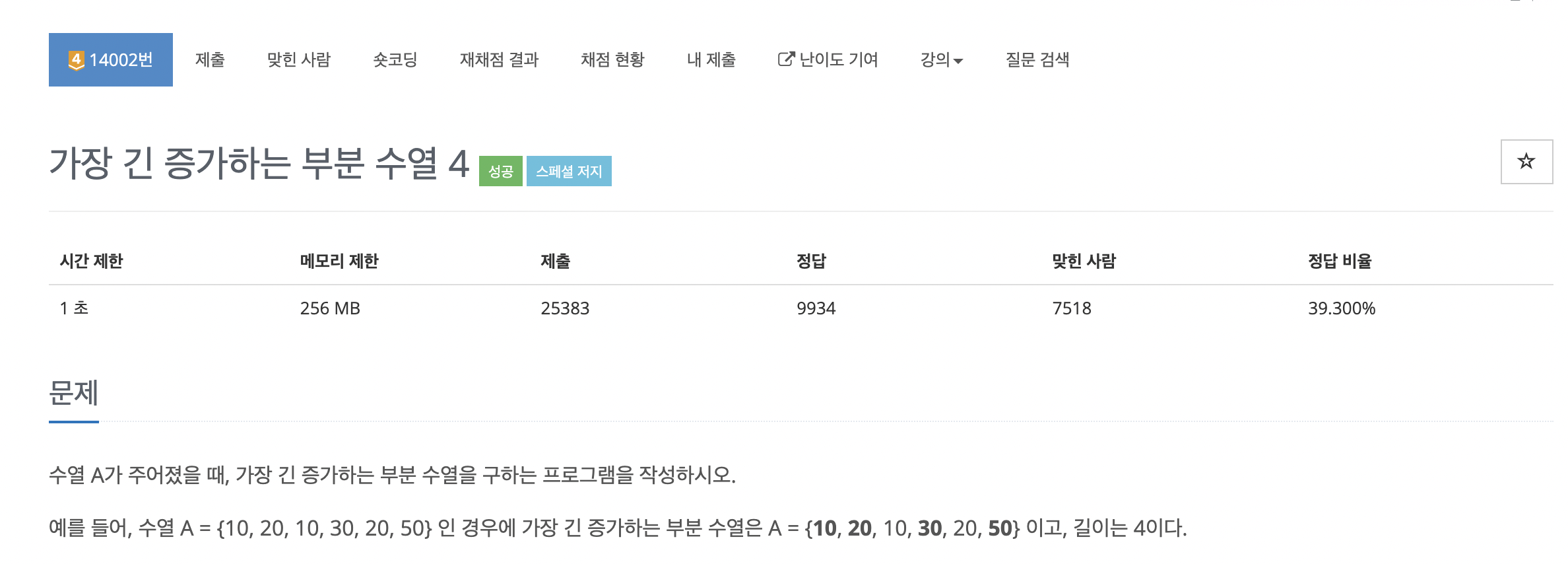
☑️ 2. Input , Output
☑️ 3. 분류 및 난이도
코딩테스트 준비-기초 : 브루트포스 - 다이나믹프로그래밍 문제입니다.
☑️ 4. 생각한 것들
- 해당 수열의 특성을 이해해야합니다.
- 만약 [20,30,280,20,40,50,70] 이라는 수열이 있다고 합시다. 가장 긴 부분수열은 [20,30,40,50,70]입니다.
이것을 가장 DP로 표현하여, 각 인덱스마다 보유하고 있는 부분수열의 길이는 [1,2,3,1,3,4,5]가 되겠습니다. 이것을 DP로 표현하는것은 ‘가장 긴 증가하는 수열’ 문제입니다. sliver2문제이므로 이 문제를 풀어서 이미 DP로 표현하는 방법은 안다고 가정합니다.
- 이것을 사이즈 별로 분류합니다. {사이즈 : 수열의 데이터} 로 나타낼때
1 2 3 4 5
{1 : 20, 20} {2 : 30} {3 : 280, 40} {4 : 50} {5 : 70}
로 나타낼 수 있습니다.
길이가 가장 큰 수열의 기준으로 아무거나 뽑습니다. 여기서는
70이 가장 긴 수열을 가지고 있으므로70을 기준으로 잡습니다. 아무거나 뽑는다라는게 굉장히 중요한데, 길이가 같기만 하다면 어떤 수열을 뽑아도 상관이 없지요. 어차피 그 보다 작은 수열은 앞에 존재하니까요. 이 부분을 이해하는것이 중요하다고 생각합니다.- 위의 방식을 이해했다면 다음 식을 세우는것은 어렵지 않습니다.
- 70을 기준으로 사이즈를 줄여가면서 그 값보다 작은 값을 추가합니다.
- 예를 들어서 5의 사이즈를 가지고 있는 70 이 처음의 기준이고 [70]
- 그 다음 4의 사이즈를 가지고 있는 50이 70보다는 작으므로 리스트에 추가합니다. 그리고 50을 기준값으로 갱신합니다. 만약 배열 뒤에 데이터가 더 있다하더라도 보지 않습니다.[70,50]
- 그 다음 3의 사이즈를 가지고 있는 {280, 40} 중에 40이 기준값인 50보다 작으므로 40을 추가하고 갱신합니다. [70,50,40] … 이런식으로 하면 됩니다.
- 이런 방식이 가능한 이유는 당연하게도 기준값보다 작은 값이 있다면 뒤에 뭐가 나오든 전혀 신경 쓸 필요가 없기 때문입니다. 이게 이해가 되지 않는다면 메모장에 직접 써가면서 우려하는 경우가 있는지 만들어 보세요. 절대 없습니다. 증가하는 수열을 자료구조에 넣었기 때문입니다.
5. code
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
from sys import stdin
from collections import deque
def solution() -> None:
# input
n = int(stdin.readline())
input_list = list(map(int, stdin.readline().split()))
# 디폴트로 가장 긴 수열은 자기 자신의 길이다. 1
dp = [1] * n
size = 1
result = []
# 초기 기준값은 맨 첫값으로 잡는다. 내림차순으로 들어왔을때를 대비.
data_dict = {1: deque([input_list[0]])}
#O(n^2)
for i in range(n):
for j in range(i - 1, -1, -1):
# 만약 현재 값이 이전 값들보다 클 때
if input_list[i] > input_list[j]:
# 갱신하면서 사이즈 별로 분류
if dp[i] < dp[j] + 1:
dp[i] = dp[j] + 1
if dp[j] + 1 not in data_dict.keys():
data_dict[dp[j] + 1] = deque()
size = max(size, dp[j] + 1)
data_dict[dp[j] + 1].append(input_list[i])
# 현재값보다 작은 경우가 없는 경우는 1로 갱신
if j == 0 and dp[i] == 1:
data_dict[1].append(input_list[i])
# 가장 긴 수열을 가지고 있는 데이터중 아무거나 뽑음.
max_num = data_dict[size][0]
# 나중에 뒤집을거니까 일단 값을 추가
result.append(max_num)
# 사이즈 분류한 것들을 돌아가면서 기준값보다 작기만하면 추가하고 빠져나옴.
for i in range(size - 1, 0, -1):
for data in data_dict[i]:
if max_num > data:
result.append(data)
max_num = data
break
print(size)
#역순 출력
print(' '.join(map(str, result[::-1])))
solution()
6. 후기
c++로 작성이 필요하거나 도움이 필요하시면 댓글을 작성해주세요.!! 기록용이라 설명이 자세하지 않습니다.
This post is licensed under CC BY 4.0 by the author.