OS복습
OS복습
1. 운영체제 ?
1. 운영체제의 목적
- 사용자 편의성 증대(사용자 입장), 컴퓨터 하드웨어 관리(컴퓨터 입장)
2. 부팅 과정
- CPU에서 ROM을 읽는다.
- ROM에는 Post(Power of Self-Test), 부트 로더(Boot Loader)가 저장되어 있음.
- Post는 전원이 켜지면 가장 처음에 실행되는 프로그램, 현재 컴퓨터의 상태를 검사
- Boot Loader는 하드디스크에 저장되어 있는 운영체제를 찾아 RAM(메인 메모리)에 가져옴.
- Post → 부트로더 과정을 부팅 과정이라고 한다.
3. 커널, 명령어 해석기
- 커널은 운영체제의 핵심, 운영체제가 하는 모든 것이 저장되어 있다.
- 명령어 해석기는 CLI, GUI 같은 운영체제에게 요청하는 명령을 해석하여 커널에 요청하고, 결과값을 출력
2. 운영체제 역사
- 배치 시스템(Batch Processing System)
→ CPU가 아무 일도 하지 않는 idle 상태가 나타나면서 비효율적 해결하기 위해 MultiProgramming System이 나옴.
- 다중 프로그래밍(MultiProgramming)
→ CPU가 어떤 프로그램을 선택해야하는 지에 대한 CPU 스케쥴링이 생겨남.
- 시분할 시스템(Time sharing System)
- 인터럽트 기반 시스템(Interrupt base System)
- 하드웨어 인터럽트
→ 마우스, 키보드로 발생시키는 인터럽트
- 소프트웨어 인터럽트
→ 직접 명령어를 쳐서 발생시키는 인터럽트
- 내부 인터럽트
→ 프로그램을 수행하다가 발생하는 인터럽트(0으로 나누는 등)
3. 이중 모드와 보호
1. 이중모드(Dual Mode)
- 사용자(User) 모드 - 비트 1, 관리자(Supervisor)모드 = 특권(Privileged)모드 - 비트 0
2. 하드웨어 보호
- 입출력 장치 보호, 메모리 보호(MMU가 관리), CPU 보호(독점 보호 - Timer를 두어 인터럽트 발생)
4. 운영체제 서비스
1. 프로세스 관리(process management)
- 프로세스 : 실제 메모리에 실행중인 프로그램, 즉 어떠한 요청에 의해 메인 메모리에 할당하여 CPU를 사용하게 되면서 사용되는 프로그램.
- 프로세스 생성, 소멸, 활동 일시 중지, 활동 재게, 통신, 동기화, 교착상태 처리
2. 주기억장치 관리(main memory management)
- 프로세스에게 메모리공간 할당, 프로세스 추적 및 감시, 메모리 회수, 가상 메모리
3. 파일 관리(file management)
- 파일 생성과 삭제, 디렉토리 생성과 삭제, 백업
4. 보조기억장치 관리(Secondary storage management)
- 빈 공간 관리(Free space management)
- 저장공간 할당(Storage allocate)
- 디스크 스케쥴링(Disk schduling)
5. 입출력 장치 관리(I/O device management)
- 장치 드라이브(device drivers)
- 입출력 장치의 성능 향상(buffing, caching, spooling)
6. 시스템 콜(System call)
- 유저 프로세스에서 운영체제 서비스가 필요로 할 때 이를 받기 위해 사용하는 호출
5. 프로세스 관리
1. 프로세스
- 프로세스 상태에는 5가지가 존재한다.
- New : 프로그램이 메인 메모리에 할당.
- Ready : 할당된 프로그램이 초기화와 같은 작업을 통해 실행되기 위한 모든 준비를 마침.
- Running : CPU가 해당 프로세스를 실행
- Waiting : 프로세스가 끝나지 않은 시점에서 I/O를 통해 CPU를 사용하지 않고 다른 작업을 한다.
- Terminated : 프로세스를 완전히 종료한다.
- PCB(Process Control Block) : 프로세스에 대한 모든 정보가 있다. TCB(Task Control Block)이라고도 함.
- 프로세스 큐(Process Queue) 에는 3가지 종류가 있다
- Job Queue : 하드디스크에 있는 프로그램이 실행되기 위해 메인 메모리 할당순서를 기다리는 큐
- Ready Queue : CPU의 점유순서를 기다리는 큐
- Device Queue : I/O를 하기 위한 여러장치가 있는데, 각 장치를 기다리는 큐가 각각 존재
2. 멀티 프로그래밍(Multiprogramming)
- Degree of Multiprogramming : 현재 메모리에 할당되어 있는 프로세스의 개수
- I/O bound Process , CPU bound Process : I/O, CPU 작업비중이 높은 프로세스를 말함.
- Medium - term scheduler : Long term 보다는 짧게 short term 보다는 자주 발생하는 스케쥴
- Context-Swtiching : CPU가 한 프로세스에서 다른 프로세스로 옮겨감.
6. CPU 스케쥴링
1. preemptive vs nonpreemptive
- 선점, 비선점 / 선점이란 어떤 프로세스가 CPU를 점유하고 있는 동안, 인터럽트, 작업이 끝난 것도 아닌데 다른 프로세스가 해당 프로세스의 CPU를 점유해버림.
- 비선점이란 프로세스가 실행 → 대기 or 실행 → 종료가 되기 전 까지는 다른 프로세스가 CPU를 점유할 수 없음.
2. Scheduling criteria
- 스케쥴링의 효율을 분석하는 기준들
- Cpu utilization(이용률) : CPU가 수행되는 비율
- Throughput (처리량) : 단위시간당 처리하는 작업의 수
- Turnaroundtime(반환량) : 프로세스가 시작하고 종료될때 까지의 시간, 적을수록 좋다.
- Wating Time(대기시간) : 프로세스가 Ready queue에서 대기한 시간
- Response Time(응답시간) : 대화형 시스템같은 시스템에서 입력에 대한 응답시간
3. Cpu Scheduling Algorithms
- FCFS(First come First Served) : 선입선저장, Non - preemptive, 이러한 것을 convey effect라고 하는 것 같다.
- SJF(Shortest-job-First) : 가장 짧은 프로세스 우선처리 → 현실적으로 불가능한 알고리즘 (각 프로세스 처리시간을 알기 힘드므로) preemptive, non preemptive 둘 다 가능하다.
- Priority : 우선순위가 높은 프로세스 먼저 처리. → 문제점 Starvation 우선순위가 낮은 프로세스는 영영 실행 안 될 가능성이 있음. → 해결방법 aging 너무 오래 기다리면 우선순위를 높여줌.
- Round Robin(RR) : 한바퀴 돌아가면서 Quantum에 따라 처리 Quantum은 10~100ms를 갖는다.
- Multilevel Queue : 프로세스는 기준에 따라 여러 그룹으로 나눌 수 있는데 이를 한 큐에 처리하는 것이 아닌 여러 큐로 처리하는 방식 / 큐마다 우선순위 지정 가능.
- Multilevel Feedback Queue : 위의 방식에서 큐에서 오래기다리면 밑의 큐로 이전, 위의 큐로 이전 하는 방식.
7. 쓰레드(Thread)
1. 프로세스의 생성과 종료
- 운영체제가 하는 일 중 하나는 초기 프로세스(init)을 생성한다.
- 새로운 프로세스를 만드는 시스템콜을 fork()라고 한다.
- 어떠한 파일을 실행하기 위한 시스템콜을 exec()라고 한다.
- 어떤 프로세스를 종료시키기 위한 시스템콜을 exit() 라고 한다.
2. 쓰레드
- 프로그램의 내부 흐름 맥
1
2
3
int main(){
cout<<"hello"<<'\n;
}
- 하나의 프로그램에 이러한 맥이 2개 이상 있는 경우를 다중 쓰레드라고 한다.
- 한 프로그램에서 이러한 쓰레드가 2개 이상 존재할 수 있는 이유는 이러한 쓰레드들이 빠르게 스위칭 되기에 한 동작으로 보이는 착시를 일으키기 때문.
- 하나의 CPU에서 이러한 스위칭이 나타나는 현상을 concurrent라고 한다.
- 여러 CPU에서 이러한 스위칭이 나타나는 현상을 simultaneous라고 한다.
- Context Switching은 프로세스 단위가 아닌 쓰레드 단위.
8. 프로세스 동기화 1
- Cooperating process : 한 프로세스가 다른 프로세스에게 영향을 주거나 받는 프로세스
- Independent process : 영향 안 받음.
- 데이터 흐름에 대한 동기화(Synchronization)이 중요.
- Bank Account Problem(은행 계좌 문제) : 공통 변수(잔액 / common variable)을 동시에 제어(concurrent update) 하는 경우 데이터가 다르게 나오는 문제.
- 공통변수를 관리하는 구역을 임계구역이라고 한다.
- 임계 구역을 해결하기 위한 3조건
- Mutual Exclusion(상호 배타) : 한 쓰레드만 접근 가능하고 다른 쓰레드는 한 쓰레드가 사용하는 동안 접근할 수 없다.
- Progress(진행) : 한 임계구역을 접근하는 쓰레드를 결정하는 것은 유한시간내에 이루어져야한다.
- Bounded waiting(유한 대기) : 임계구역으로 들어가기 위해 대기하는 쓰레드들은 유한시간내에 들어갈 수 있어야한다.
- 세마포어 : 대표적인 동기화 도구 P, V로 나뉨.
- P : value를 감소시키고 0보다 작아지면 해당 임계구역에 다른 프로세스가 존재한다는 의미이므로 접근하지 못하도록 막는다.
- V : value를 1증가시키고 0보다 작거나 같으면 임계구역에 접근하려는 프로세스가 큐에 있으므로 꺼내서(wake) 수행한다.
- 일반적으로 Mutual Exclusion을 위해 사용된다. ordering(실행순서 제어)를 위해서도 사용된다.
9. 프로세스 동기화 2
1.생성자 소비자 문제
- bouned buffer(크기가 정해진 유한 버퍼)에서 생산자와 소비자가 같은 버퍼에 있는 자원(buffer 자체, 데이터 갯수 등)에 접근하면서 동기화 문제가 생긴다.
- 세마포어로 해결이 가능하지만, busy waitng 문제가 생김.
- busy waiting이란 생산자가 소비자가 접근하기 전 버퍼가 비어있는 지에 대한 함수. 무한루프구문이라 비효율적이다. 이를 해결하는 것도 세마포어 → full, empty라는 세마포어를 더 둠.
2. Readers - writers 문제
- 데이터베이스는 여러 프로세스가 접근하기 때문에 동기화 문제가 생기는데 이를 방지하고자 Mutual Exclusion을 하면 데이터베이스의 비효율적 문제가 생긴다.
- 때문에 Reader는 읽기만 하므로 여러 reader프로세스가 접근하는 것은 허용하지만, Writer는 데이터를 수정하므로 Mutual Exclusion을 보장한다.
- Reader와 Writers가 동시에 들어올 때 알고리즘이 있다.
- The First R/W problem(Reader 우선순위), The Second R/W problem(Writers 우선순위), The Third R/W problem(우선순위 없음)이 있음.
3. Dining Philosopher Problem
- 식사하는 철학자 문제, 각 테이블에 학자 5명과 젓가락 5개가 있고 식사를 하려면 젓가락 2개가 필요할 때 모든 학자가 식사하려면?
- 학자가 왼쪽 젓가락과 오른쪽 젓가락을 순서대로 들고 식사를 마치고 똑같은 순서로 젓가락을 놓을 때 해결가능.
- 하지만 Starvation 문제가 발생. 학자가 동시에 젓가락을 들어버리면 교착상태(DeadLock)상태가 걸려버림.
10. 프로세스 동기화 3
1. 교착상태 필요조건
- 4가지에 해당된다해서 무조건 교착상태에 걸리는 것은 아니다.
- Mutual Exclusion(상호 배타) : 한 프로세스가 자원을 사용하고 있으면 다른 프로세스는 접근할 수 없다.
- Hold and wait(보유 및 대기) : 한 프로세스가 자원을 가지고 있는 상태에서 대기한다.
- No Preemptive(비선점) : 한 프로세스가 자원을 수행하는 도중에는 다른 프로세스가 끼어들 수 없다.
- Circular wait(환형대기) : 프로세스가 요구하는 자원의 방향들이 원형을 이룸.
2. 교착상태 처리
- 교착상태 방지(DeadLock prevention)
- 상호배타를 방지하려면 자원을 공유하게 만들어야하는데 사실상 불가능.
- 보유 및 대기를 방지하려면 자원을 할당할 수 있는 곳에만 할당하고, 자원을 반납 받음. 하지만, 자원의 활용률을 저하시키고 Starvation을 발생시킬 수 있다.
- 비선점을 방지하는 것은 사실상 불가능.
- 환형대기를 방지하기 위해서는 자원에 번호를 붙여 오름차순으로 자원을 할당 등 방법을 사용. 하지만 자원 활용률을 저하시킬 수 있다.
- 교착상태 회피(DeadLock Avoidance)
- 교착상태를 자원 요청에 대한 잘못된 승인으로 판단.
- 안전한 할당(Safe allocation)과 불안전한 할당(Unsafe allcation)- 결국 교착상태에 빠짐이 있다.
- 교착상태 회피를 Banker’s Algorithms 이라고도 함.
- 교착상태 검출 및 복구(Dead Lock Detection & Recovery)
- 주기적으로 교착상태가 발생하였는 지 검사한다.
- 교착상태 무시
- 교착상태가 잘 발생하지 않고, 해결하는데 오버헤드가 발생하므로 그냥 교착상태를 무시해버림.
11. 모니터 는 생략. condition queue, mutual exclusion queue 이해.
12. 주기억장치 관리
- 논리주소 : CPU가 사용하는 주소
- 물리주소 : 실제 메모리에서 사용하는 주소
- 동적적재 : 프로그램이 실행하는데 반드시 필요한 루틴/자원 적재.
- 동적연결(DLL) : 여러 프로그램에서 사용되는 공통 라이브러리를 하나의 라이브러리로 메모리에 올림.
- swap out : 메모리 → Backing store
- swap in : Backing store → 메모리
- 메모리에 여러 프로세스를 올리다보면 단편화문제가 생김.
- 외부 단편화 : 남은 메모리들을 모으면 프로세스를 할당할 수 있는 문제.
- 메모리 할당방식
- First Fit
- Best Fit : 이 방식을 사용해도 전체 메모리의 1/3 낭비.
- Worst Fit
- Compaction : 여러곳에 흩어져 있는 hole을 모으는 방법. 하지만 hole을 옮기는데에 오버헤드가 크고, 옮기는 방식에 대한 최적의 알고리즘이 없음.
13. 페이징
- Compaction이 사용하기 어렵기에 고려된 방법.
- 프로세스를 작은 크기로 나눠서 외부 단편화를 해결하려는 방식
- 프로세스를 나눈 조각을 page, 메모리를 나눈 조각을 frame이라고 한다.
- cpu가 나눠진 프로세스 조각을 주소변환을 통해 받아 프로세스를 실행한다.
- 페이징은 내부 단편화 발생.
- 프로세스의 크기가 프레임의 크기의 배수가 아닐 경우 발생. 마지막 페이지는 마지막 프레임에 전부 채워질 수 없다.
- 하지만 최악의 경우 페이지의 크기-1 만큼 메모리 낭비가 있고, 이는 무시할 수 있다.
- 보호와 공유
- 보호는 페이지테이블에 r,w,x에 대해 비트를 두어 해당 비트가 활성화 되어있는 경우에만 작업이 가능. 활성화 되어 있지 않은데 작업을 하려는 경우 인터럽트.
14. 세그멘테이션
페이징은 프로세스를 물리적으로 나누어 작업을 하였지만, 세그멘테이션은 논리적(code+stack +data영역 등)으로 나누어 메모리에 배치.
- 하지만 현재는 페이징 기법을 많이 쓴다. 이유는 세그멘테이션은 논리적으로 나누기에 크기가 다양하다. 이로인해서 외부 단편화가 발생하기 쉽다.
- 페이징과 세그멘테이션을 합친 페이징 세그멘테이션 방법이 있지만, CPU → 세그멘테이션 테이블 → 페이징테이블을 거쳐야하는 단점이 존재한다.
15. 가상 메모리
필요한 부분만 메모리에 올려 적재하여 메모리 낭비를 줄여 실행시키는 방식.
- 지역성의 원리(Locality of reference) : 메모리 접근은 시간적 지역성과 공간적 지역성으로 나뉨.
- 시간적 지역성 : CPU는 어느 메모리를 읽은 후 다시 그 메모리를 읽을 확률이 높다는 것.
- 공간적 지역성 : CPU가 메모리를 읽을 때는 인접한 범위에서 읽는다는 것. (프로그램이 대체로 절차적으로 만들어져 있어서)
16. 페이지 교체 알고리즘
- FIFO
- Belody’s anomaly : 프레임 수가 증가하면(메모리가 커지면) page fault 수가 줄어들어야 정상이지만 오히려 커지는 현상.
- OPT(optimal) : 가장 오래동안 사용되지 않을 페이지를 교체하는 방식이지만 현실적으로 불가능.
- LRU(Least- Recently - Used) : 최근에 사용되지 않으면 나중에도 사용되지 않을 것을 교체 (대부분 LRU사용.
17. 프레임 할당
Global Replacement vs Local Replacement : Global은 메모리상의 모든 프로세스에 대해 교체, Local은 메모리상의 자기 자신의 프로세스에 대해 교체 / 일반적으로 Global이 메모리 사용 효율성이 좋음.
프레임 할당
- 쓰레싱(Thrashing)
- 메모리에 올라가는 프로세스가 많을수록 CPU사용률이 올라가야한다고 생각하지만 일정 범위를 넘어가면 그와 반대로 오히려 사용률이 내려가는 현상.
- 메모리와 Back Store 사이에서 I/O 작업이 일어나는데, 이는 CPU를 사용하지 않으므로 프로세스가 반복되면 위의 작업이 계속 반복됨. → CPU가 사용되지 않는 경우가 생김.
- 해결 방법은 2가지
- Global 대신 Local Replacement를 쓴다. → 메모리 사용 효율성이 낮아짐.
- 프로세스당 충분한적절한 프레임을 할당.
- 이 또한 2가지 할당 방법이 있다.
- 정적 할당(Static Allocation) : 동일 할당 : 모든 프로세스에 똑같이 할당, 프로세스의 크기가 전부 다르므로 비효율적 / 비례 할당 : 프로세스의 크기에 따라 할당. 프로세스의 크기가 크더라도 전부 사용하지 않으므로 비효율적
- 동적 할당(Dynamic Allcation) : 실행중에 프레임 할당. 특정 시간대에는 일정 범위의 페이지를 주로 참조한다는 점을 이용. 프로세스를 미리 실행해봐야 안다는 단점 때문에 나온 것이 Working set방식 - 미래가 아닌 과거를 봄
- 프로세스당 충분한적절한 프레임을 할당.
PFF(Page - Fault - Frequency) : 상한선(upper bound)와 하한선(lower bound)를 설정하여, 상한선보다 많은 페이지 부재가 발생하면 프레임 할당을 많이해주고, 하한선보다 적은 페이지 부재가 발생하면 프레임 할당을 줄여줌.
- 페이지 크기에 따른 성능
- 내부 단편화 : 내부 단편화를 줄이려면 페이지 크기는 작은 것이 좋다.
- Page-in, Page-out 시간 : 페이지 크기가 크면 클수록 한 번의 Seektime마다 많은 페이지를 읽을 수 있으므로, 페이지 부재 빈도가 줄어듦.
- 페이지 테이블 크기 : 페이지 크기가 클수록 페이지의 개수는 줄어드므로, 그만큼 페이지 테이블도 줄일 수 있다.
- Memeory resolution(해상도) : 메모리에 필요한 데이터가 있을 확률. 페이지 크기가 작을수록 높다. 페이지 크기가 크면 다른 필요없는 부분이 있을 확률이 크기 때문.
- Page Fault 발생확률 : 발생확률을 줄이려면 페이지의 크기가 큰 것이 좋다. 대부분 프로세스는 일정 범위 이내인 경우가 많으므로 페이지 크기가 크면 필요한 부분이 있을 확률이 높다.
18. 파일 할당
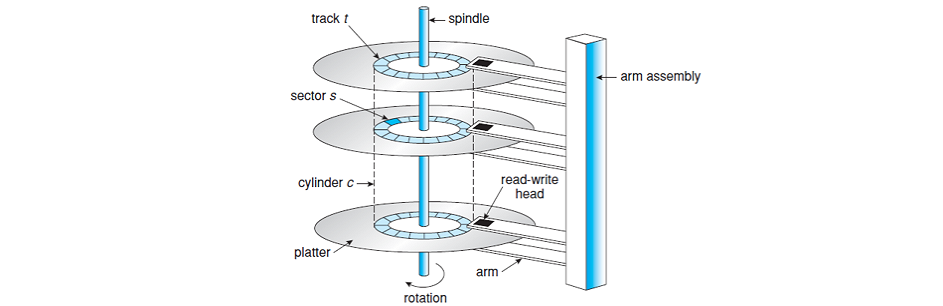
- platter: 실제 데이터를 기록하는 자성을 가진 원판이다. platter는 그림과 같이 여러 개가 존재하고 앞뒤로 사용할 수 있다. 한 platter는 여러 개의 track으로 이루어져 있다.
- track: platter의 동심원을 이루는 하나의 영역이다.
- sector: 하나의 track을 여러 개로 나눈 영역을 sector라 한다. sector size는 일반적으로 512 bytes이며 주로 여러 개를 묶어서 사용한다.
- cylinder: 한 cylinder는 모든 platter에서 같은 track 위치의 집합을 말한다
앞서 sector는 여러 개로 묶어서 사용한다고 했는데, 이를 블록(block)이라 한다. 하드디스크는 블록 단위로 읽고 쓰기 때문에 block device 라고 불리기도 한다.
따라서 디스크는 비어있는 블록들의 집합이라고 볼 수 있다.(pool of free blocks) 그렇다면 운영체제는 각각의 파일에 대해 free block을 어떻게 할당할까?
파일 할당
- 연속 할당(Contiguous Allocation) :
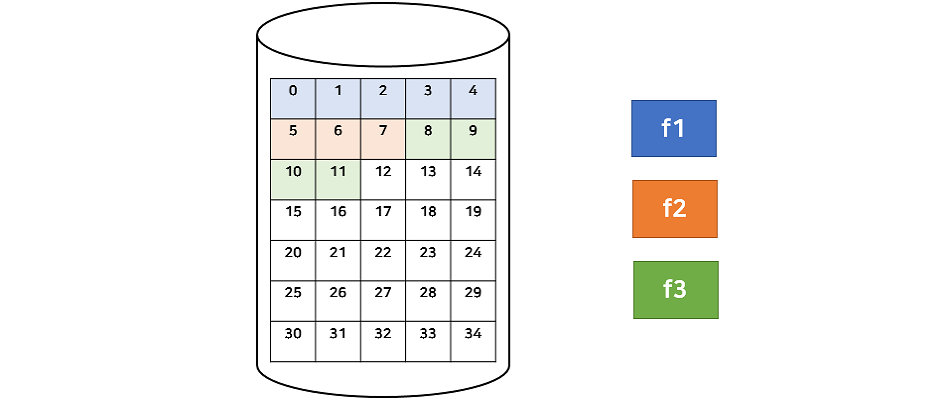
장점 : 디스크 헤더의 이동 최소화 → I/O 성능을 높일 수 있다, 순차접근, 직접접근 가능.
단점 : 파일을 할당하고 지우고를 반복하다보면 중간 중간에 빈 공간(hole)이 생기는데 연속 할당은 연속된 공간을 찾아야 하기 때문에 이전 메인 메모리 할당에서 살펴본 것과 같이 외부 단편화 문제가 발생한다., 또 다른 문제는 파일을 저장할 때 실제 크기를 알 수 없다. 특히, 계속해서 사용하는 파일의 경우 크기가 계속 증가 할 수 있기 때문에 이를 지속해서 연속적으로 할당하기에는 매우 부적절하다.
- 연결 할당(Linked Allocation) :
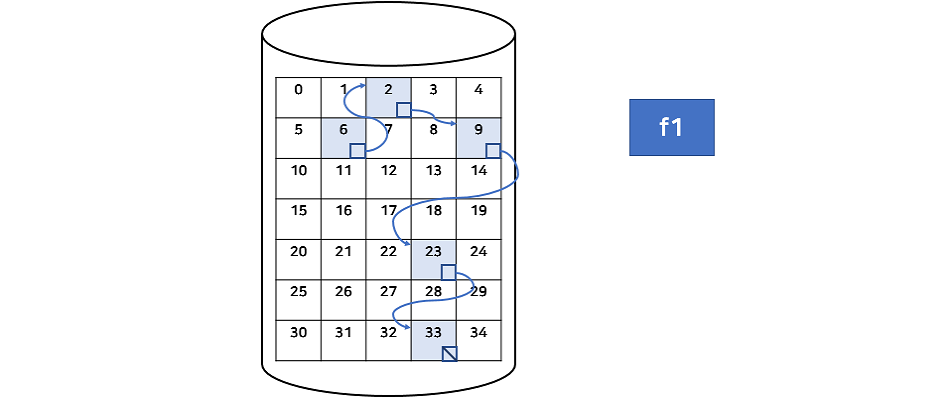
장점 : 파일이 커져도 블록을 연결만 해주면 되므로 외부 단편화가 없다.
단점 : 순차 접근은 가능하지만, 직접 접근은 불가능. 포인터를 저장하는 4byte이상의 손해 발생. 낮은 신뢰성(링크가 도중에 끊어버리는 경우), 낮은 속도(포인터를 계속 옮기면서 읽는 과정)
- FAT(File Allocation Table) : 연결 할당의 단점 보완.
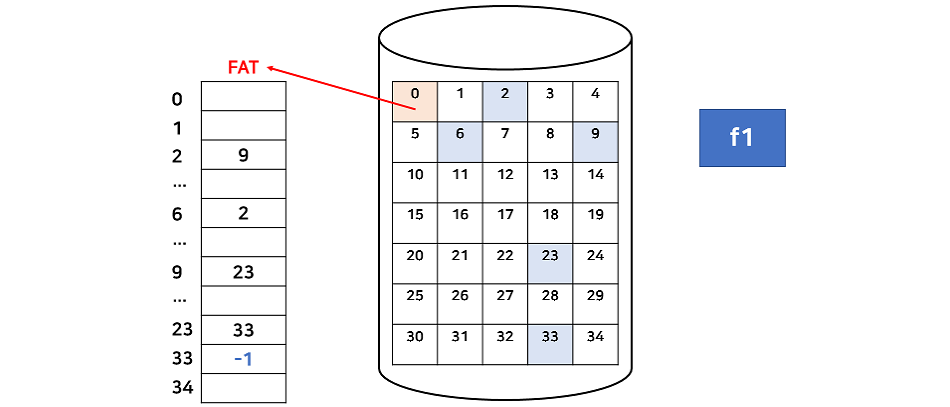
FAT 시스템은 다음 블록을 가리키는 포인터들만 모아서 하나의 테이블(FAT)을 만들어 한 블록에 저장한다.
FAT 시스템을 사용하면 기존의 연결 할당의 문제점 대부분을 해결할 수 있다. FAT를 한 번만 읽으면 직접 접근이 가능하고, FAT만 문제가 없다면 중간 블록에 문제가 생겨도 FAT를 통해 그 다음 블록은 여전히 읽을 수 있다. 그리고 FAT는 일반적으로 메모리 캐싱을 사용하여 블록 위치를 찾는데는 빠르지만 실제 디스크 헤더가 움직는 것은 블록이 흩어져 있으므로 여전히 느리다고 볼 수 있다. 마지막으로 FAT는 매우 중요한 정보이므로 손실 시 복구를 위해 이중 저장을 한다.
- 색인 할당(indexd Allocation)
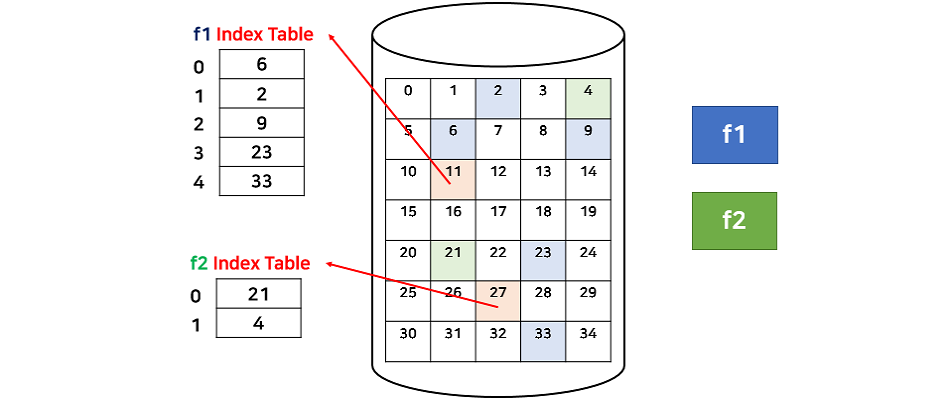
색인 할당은 인덱스 블록에 할당된 블록을 순서대로 저장하기 때문에 직접 접근이 가능하다. 그리고 연속적으로 할당할 필요가 없으므로 외부 단편화 문제 또한 발생하지 않는다. 색인 할당은 Unix/Linux에서 주로 사용한다.
색인 할당의 단점은 작은 크기의 파일인 경우에도 하나의 블록을 인덱스 블록으로 사용하기 때문에 저장 공간이 손실된다. 그리고 하나의 인덱스 블록을 가지고는 크기가 큰 파일을 저장할 수 없다.
이를 해결하기 위해 Linked, Multilevel index, 둘을 합친 Combined 방식이 있다. 리눅스는 Combined방식.
19. 디스크 스케쥴링
디스크에 접근하는 시간은 Seek time(탐색 시간) + rotational delay + transfer time 으로 계산할 수 있는데, 이 중에서 seek time(head를 움직이는 시간)이 가장 크다.
디스크 탐색 시간을 줄이기 위한 방법들을 디스크 스케쥴링이라고 한다.
- FCFS(first Come First Served) : 가장 공평하고 간단한 방법.
- SSTF(Shortest Seek Time First) : 현재 헤더가 다음 요청을 처리하기 위해 움직여야하는 거리가 가장 짧은 것을 선택. - 최적의 알고리즘 아니다.
Scan(헤드가 지속적으로 디스크를 앞뒤로 검사)
1 C-Scan : 한 방향으로만 움직이는 것이 마치 원형과 같다. 움직이는 거리는 더 길어질 수 있지만, 처음 위치로 되돌아갈 때에는 데이터를 읽지 않으므로 더 빠른 속도로 이동가능
2 Look : Scan알고리즘은 한 방향으로 가기에 0번째 실린더까지 이동하는 데 이는 불필요한 이동이다. 최소 범위와 최대 범위를 지정하여 Scan하는 방식을 Look.
참고 : scan예제
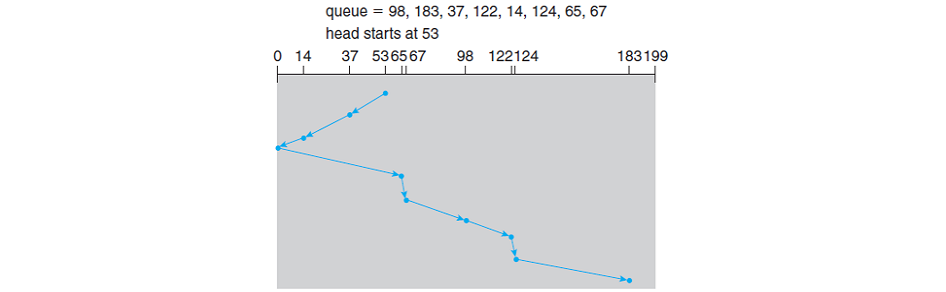
- 3C-Look : Look에서 Circular를 추가한 것으로 위의 Look의 최소, 최대 범위에서 한 방향으로만 이동한다.