HTTP - 2 URL와 웹 브라우저 요청 흐름
해당 자료는 인프런 김영한 선생님의 모든 개발자를 위한 HTTP 웹 기본 지식 강의노트입니다.
1. URI
URL는 로케이터(locator), 이름(name)또는 둘 다 추가로 분류될 수 있다.
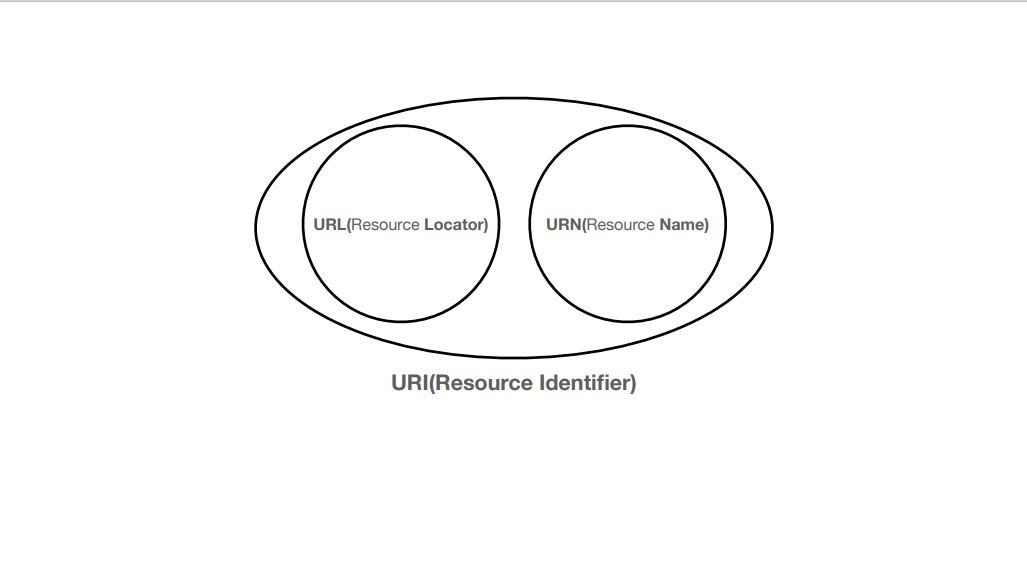
이렇듯 URI는 URL과 URN을 포함합니다.
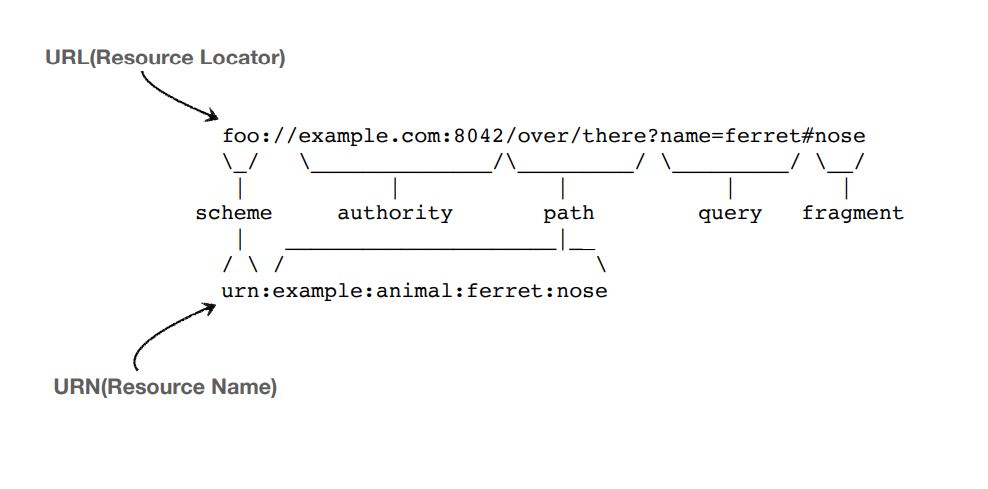
둘의 방식은 위와같은 차이점이 있으며, URN은 거의 쓰이지 않으므로 저런 패턴으로 구사하는 지를 알아두면 됩니다.
URI
Uniform : 리소스 식별하는 통일된 방식
Resource : 자원, URI로 식별할 수 있는 모든 것
Identifier : 다른 항목과 구분하는데 필요한 정보
URL - Locator : 리소스가 있는 위치를 지정
URN - Name : 리소스에 이름을 부여
URN 이름만으로 실제 리소스를 찾을 수 있는 방법이 보편화 되지 않았습니다.
URL 예시는 다음과 같습니다.
https://www.google.com/search?q=임창정&hl=ko
URL 문법
scheme://[userinfo@]host[:port][/path][?query][#fragment]
https://www.google.com/search?q=임창정&hl=ko
scheme : 주로 프로토콜 사용, http는 80포트, https는 443포트를 주로 사용, 포트는 생략 가능합니다.
프로토콜이란 어떤 방식으로 자원에 접근할 것인가를 약속하는 규칙입니다.
https는 http에 보안이 추가된 것입니다.
userinfo : URL에 사용자 정보를 포함해서 인증할 때 사용하지만 거의 사용하지 않습니다.
host : 호스트명, 도메인명, IP 주소를 입력
port : 위에서 언급한 것처럼 생략이 가능하고, 생략할 땐 http : 80, https : 443으로 생각하고 생략해야합니다.
path : 리소스 경로, 계층적 구조
/home/file1.jpg
/users -> user전부를 보여주는
/users/100 -> 100번째 user를 보여주는
query : key=value 형태, ?로 시작, &로 추가 가능, 보통 query parameter, query string 등으로 불립니다.
fragment : 잘 사용하진 않고, html 내부 북마크에서 사용.
아마 html을 문단으로 나눠서 보여주는 형식을 말하는 듯 합니다.
2. 웹브라우저 요청 흐름
https://www.google.com/search?q=임창정&hl=ko
이 문장을 갖고 흐름을 정리하면
- 웹 브라우저가 리소스 요청 시 HTTP 요청 메시지 라는 것을 생성

저번 포스팅에서 쓴 네트워크 흐름대로 흘러갑니다.
- SOCKET 라이브러리, 3way handshake를 통해 서버와 연결
- TCP/IP 연결
- HTTP 메시지가 포함된 TCP/IP 패킷 생성
- 패킷 정보가 인터넷으로 들어감.
- 서버에 요청 패킷이 들어오면 껍데기(패킷들)은 버리고, HTTP 메시지를 확인
- HTTP 메시지 요청에 따라 응답패킷을 생성해서 보냄.
- 많은 노드들을 통해 응답 패킷이 클라이언트에 도착하고 클라이언트도 마찬가지로 패킷들은 버리고 메시지를 확인하여 HTML 렌더링을 통해 화면에 보여짐.