aws를 이용해서 음원 스트리밍 파일 서버(?) 구축하기
📖 개요
내가 하고 있는 프로젝트중 하나인, bpm을 측정해서 해당 bpm에 맞는 음원을 반환하는 서비스는 기존에 다음과 같은 로직으로 되어있었다.
1
s3에 파일업로드 -> 직접 접근할 수 있는 url을 안드로이드에 반환 -> 안드로이드에서 캐시작업 + 해당 음원을 다운로드 -> 음원 재생
여기서 문제는 2가지 있었다.
- 캐시작업
캐시 작업을 할 때 안드로이드에서 리소스 부담이 크다는 것이다. 음원이 하나당 10MB정도인데, 100곡이면 1GB라는점 그리고 캐시작업으로 인해 코드가 더럽다고 한다.
- 음원재생
이것도 가장 큰 문제인데, 음원을 다운로드하고 재생하는 방식이다보니 다음 곡 재생이 4~5초 걸린다고 하는 것이다.
4~5초가 크지는 않지만 이게 반복된다면 사용자 입장에서 굉장히 불편할거라 생각했다.
그래서 우리는 스트리밍방식을 선택하기로 하였다.
📖 선행지식 및 flow
선행지식에 대해 많이 적지는 않겠지만 hls라는 프로토콜을 사용해서 스트리밍 방식을 구현한다.
인터넷에 찾아보면 비디오 파일을 스트리밍방식으로 구현한 예제는 많이 찾아볼 수 있지만, mp3파일을 스트리밍방식으로 구현한 예제는 찾기 어려웠다.
그래서 비디오 파일을 스트리밍방식으로 구현한 예제를 토대로 작성하였다.
플로우는 다음과 같다.
1
aws Lambda에서 s3에 파일 업로드를 감지 -> 파일 업로드 되면 mp3파일인 경우 Elastic TransCoder를 통하여 m3u8파일로 변환 -> 이에 직접 접근 가능한 url을 클라이언트에 제공
그러면 먼저 aws Lambda를 작성해야한다.
Aws Lambda작성
Lambda를 통해 s3에 파일이 업로드되는 것을 감지하고, 해당 파일을 m3u8파일로 변환한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
# Python
import boto3
def lambda_handler(event, context):
# AWS Elastic Transcoder 인스턴스 생성
transcoder = boto3.client('elastictranscoder', region_name='us-east-1')
# 변환 작업에 사용할 S3 버킷 이름 설정
input_bucket = '버킷 이름'
output_bucket = '버킷 이름'
# Lambda 이벤트에서 S3 버킷 이름과 파일 키 추출
bucket = event['Records'][0]['s3']['bucket']['name']
key = event['Records'][0]['s3']['object']['key']
# 버킷명 출력
print("bucket:", bucket)
# s3에 업로드된 파일명 출력
print("key:", key)
# 필자의 경우 album이미지가 들어오는 경우 따로 저장해줘서 이는 걸러줌.
print("key find test :", key.find("album"))
if key.find("album") != -1 :
return
# 이 밑은 출력파일 경로 본인이 알아서 설정.
key = key.replace("+"," ").replace(".mp3", "")
keyList = key.split("/")
outputFolder = keyList[1] + "/" + keyList[-1]
print(outputFolder)
#여기까지
# Elastic Transcoder 작업 설정
job_settings = {
'PipelineId': 'Elastic TransCoder 파이프라인 ID',
'Input': {
'Key': key,
'FrameRate': 'auto',
'Resolution': 'auto',
'AspectRatio': 'auto',
'Interlaced': 'auto',
'Container': 'auto'
},
'Output': {
# 출력 파일명
'Key': "output/" + outputFolder +"/Hls",
# 비디오 파일 프리셋 아이디명인데, 밑의 ID는 Hls Audio 160k이다.
'PresetId': '1351620000001-200060',
'SegmentDuration': '10',
'ThumbnailPattern': '',
'Rotate': '0'
}
}
# Elastic Transcoder 작업 시작
transcoder.create_job(
PipelineId=job_settings['PipelineId'],
Input=job_settings['Input'],
Output=job_settings['Output']
)
return {
'statusCode': 200,
'body': 'Elastic Transcoder job created'
}
한글로 적은 부분은 본인이 알아서 적어야하는 부분이다.
Elastic TransCoder 파이프라인 ID를 알려면 AWS Elastic TransCoder로 접근해서 파이프라인을 생성해야한다.
만드는 방식은 크게 어렵지 않으며, 성공적으로 만들면 해당 파이프라인의 ID가 생성된다.
이는 파이프라인을 선택하면 돋보기 모양이 생기는데 거기 안으로 들어가면 볼 수 있다.
![]()
해당 ID를 입력해주면 된다.
이렇게 하면 s3에 api콜을 통해서 파일을 업로드하던, 직접 업로드하면 람다가 작동해서 성공적으로 m3u8파일로 변환된다.

이를 테스트하는 방법은 HLSPlayer를 다운받아서 해당 url에 직접 접근하였을때 음원이 재생되면 된다.
겪은 문제?
위처럼 깔끔하게 되지는 않을 것이다.
중간에 IAM 역할이 없다고 오류가 나온적도 있으며, 코드상의 문제가 생긴적도 있었다.
이는 전부 AWS CloudWatch에서 로그를 분석하거나, AWS Elastic Coder의 JOB에서 로그를 볼 수 있다.
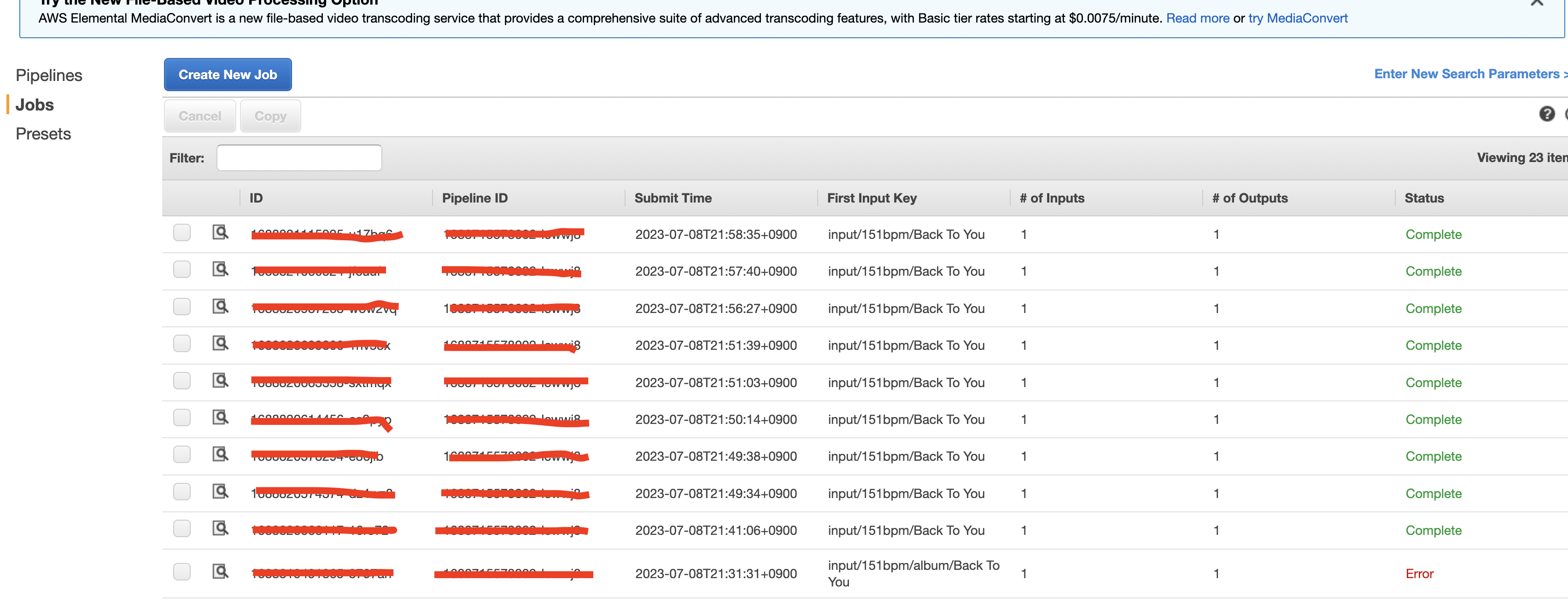
AWS Elastic Coder 로그 접근
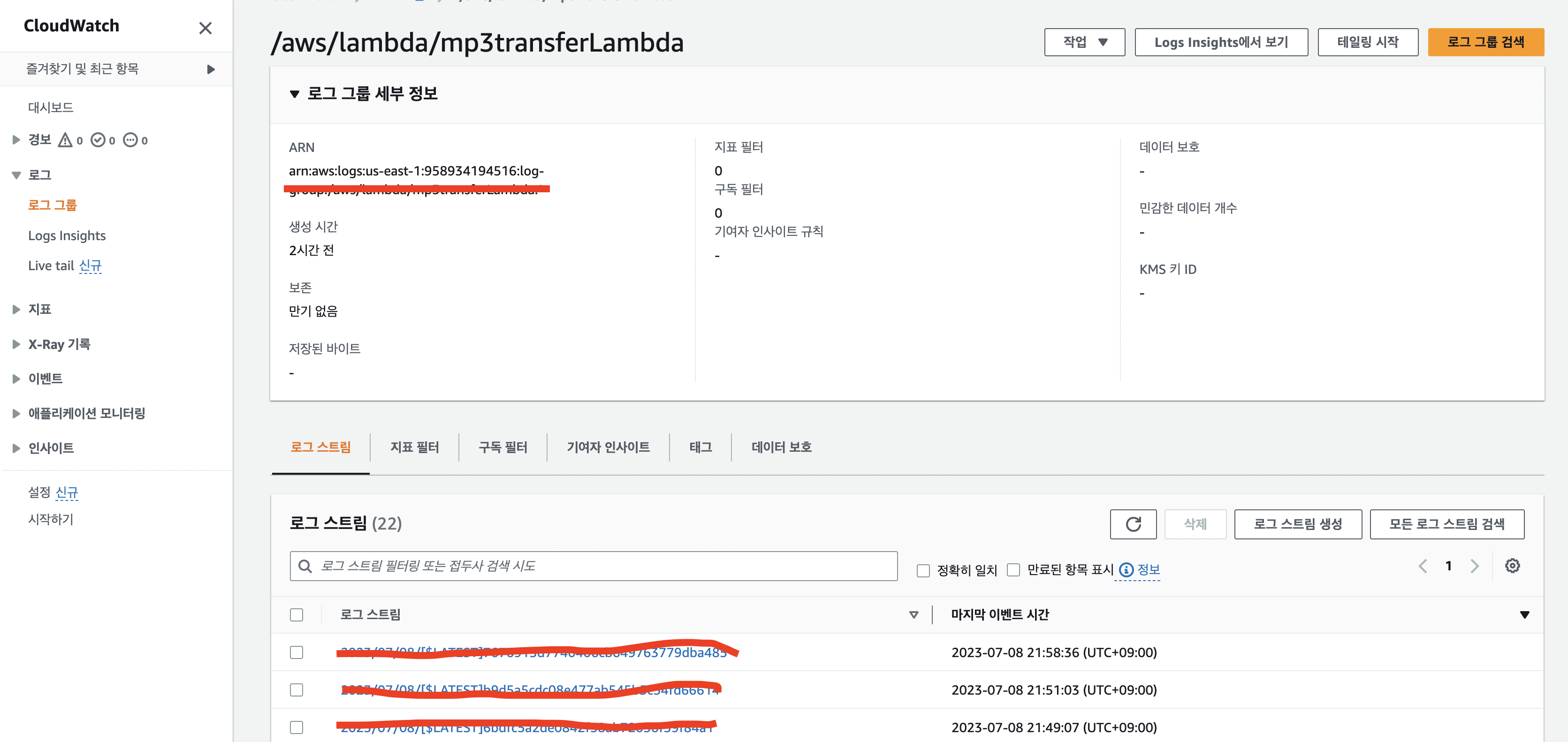
AWS CloudWatch로 접근해서 보는 로그 분석
큰 어려움이 있다면 댓글을 달아주세요.